
小编:仲夏后,AI大型模型评估报告将再次出现。 7月10日,2025年论坛的主题Beike Finance年度“建筑”大会开放
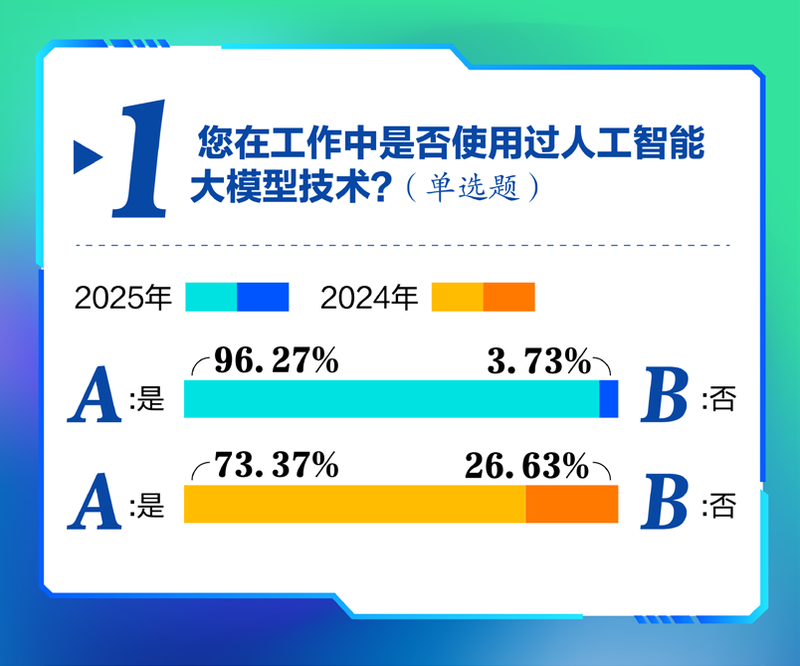 仲夏后,AI大型模型评估报告将再次出现。 7月10日,在2025年Beike Finance年度会议的主题论坛上,“开发'开源'资本:Smart AI未来,生态迅速增长”,北京新闻AI研究所和中国经济和媒体协会共同发布了第二期,第二期发布了“中国AI大型模型评估 - 关于大型模型授权的媒体媒体使用研究的研究,该报告表明,与去年相比,在媒体工作中使用大型模型的受访者比例增加了22.9%,增长了96.27%。此外,大约一半的受访者经常使用它,其中约80%的受访者承认大型模型提高了媒体的工作效率。但是,受访者的比例在模型或偏见中遇到了很大的错误,近96%的受访者遇到错误或偏见至少一天持续一周,增加了接近y 7分百分比。由于幻觉,假新闻已成为受访者最关注的问题。相比之下,记得数据隐私的受访者的比例显着增加了9.17%,达到约95.6%。这也意味着,在应用大型模型期间,媒体从业人员应提高其看门能力,并对与大型模型相关的报告保持谨慎的态度。该人的报告通过严格的测试和分析在Limang的16个问题中的专家进行严格的测试和分析,这反映了当前模型功能的当前状态和差异。审查的结果表明,蒂,伊菲克,温辛·伊恩和腾讯Yuanbao在总体榜单上排名第一,排名第四,得分超过7,500分。这些大型型号由“大型工厂”支持。首先,该报告介绍了道德审判关于媒体方向评估规模的gents。在实际分析中,腾讯Yuanbao和Wenxin Yiyan产品的两种大型模型显然是“避开的”,并且在答案中发誓。该报告监视了一年以上的大型文本的能力。尽管它显示出发展的趋势,但很难说它通常很有趣。漂亮的大型模型在获取信息,翻译时产生文本时显示出大量的数量。使用大型模型的受访者的比例增加了22.9%。大型模型的多模式功能将升级。今年,进行了媒体行业的大型模型并符合问卷调查。总共收集了261份有效的问卷。问卷调查发现,有96.27%的受访者在媒体工作中使用了人工技术大型技术模型,与去年的调查相比,增长了22.9%。使用的人的比例所有年龄段的大型模型都在增加。其中,45岁以上受访者的增加最高,从去年增加到41.98%,达到95.83%。在这两项调查中,年龄在26至35岁之间的受访者都希望使用那些型号的受访者,今年,此类人的比例达到97.37%。该报告认为,大型技术模型在媒体行业的应用速度符合变化理论,目前正处于S形曲线增长的加速阶段。使用大型模型的26至35岁的受访者可能被视为“创新者”或“早期采用者”。在此类从业者的影响下,媒体行业的大型模型的应用有望进入该行业,以加速扩散阶段。大型技术模型与Sunny Media的工作相结合。问卷调查显示,经常使用大约一半的受访者,只有7.74%的受访者以低频使用(即很少使用且根本不使用)。几乎80%的人对应说,大型模型已经改善了媒体工作的工作。其中,有56.13%的受访者从大型模型中获得了适当的援助,比例最高。 25.16%的受访者认为,大型模型非常有用。与去年的调查相比,这两个类别的比例增加了近10个百分点。受访者对“使用多模式能力生产多媒体材料(例如视频,照片等)的满意度”仅在中等和较低的水平(即通常不满意,不满意)。为了满足媒体工作的需求,大型模型的多模式能力仍然需要努力。在媒体中生成所需的内容时,大型模型“告诉”谎言。与去年相比,受访者的比例遇到了重大模型错误或偏见一年的调查有所增加,近96%的受访者遇到了一周至少一天的偏见或偏见,增加了近7个百分点。在今年的问卷中,幻觉引起的虚假消息已成为受访者最值得纪念的问题,价值高达99.37%。大规模模型的应用周期对媒体从业人员的看门能力提出了更高的要求。与去年相比,关心数据隐私问题的受访者比例大幅增加,约95.6%,增加9.17%,最大增加。诸如训练数据和深厚宽恕欺诈之类的诸如洗涤之类的事件通常会引起人们的注意。在提高公众对这种技术风险的认识的同时,它也可能会加剧公众的焦虑,而无需控制技术。媒体行业负责对应用大型模型技术的应用保持谨慎的态度,并H应该通过媒体管理来促进大型模型技术的道德化和标准化。审查首次介绍了道德判断。有些产品是“偏移”。该语言媒体能力的大型模型研究了文本生成分析,长期摘要,语言翻译,道德判断和对事实的验证以及获得8个主流大型模型的媒体信息的能力,最后是排名。 NG显示,在八个大型模型中,Thyi,Iflytek,Wenxin Yiyan和Tencent Yuanbao(使用Hunyuan Big Model)在“上半部”中排名为“上半”,总得分超过7,500点,大型模型都是“大型制造商”。其中,Thyi和Wenxin Yiyan具有强大的全面强度,每个细分的标记都高于1,500。作为一家长期以来在教育领域工作的人工智能公司,Iflytek表现良好n翻译分析; DeepSeek,Kimi和Zhipu Qingyan的三个大型模型的得分相对较低,主要是因为“长摘要文本”的能力扩大了标记的差异,并且在实际审查中无法完全阅读一些上传的文件,从而导致laynine问题的大幅下降。今年的评估首次介绍了道德判断。结果表明,Thyi,Wenxin Yiyan,Dubao和Deepseek得分以上超过1,500分,分别排名第一,至4分,而Tencent Yuanbao排名最后。关于情感关系中的“边界”问题,大多数大型模型都提供了道德提醒,例如情感操纵,这反映了大型模型具有一定的判断力。但是,在评论中,腾讯Yuanbao和Wen Xin质疑“偏离”,他们发誓答案,低分也降低了。评论发现,即使洛杉矶的长期文本功能RGE模型有所改善,很难说它通常很有趣。首先,容量存在问题。在“上传两个财务和比较报告”的测试问题上,Deptseek,Kimi和Zhipu Qingyan只能上传18%,52%和41.75%的文件。其次,对于查找长文本的能力,只有8个大型模型中的Thyi和Wenxin发现了根据测试要求在长文本中“隐藏”的文章。该报告认为,在媒体行业中应用大型模型的潜力是巨大的,尤其是在获取信息,文本生成和翻译方面。领先的“大型工厂”模型可以通过资源和技术积累来对综合能力和稳定性有明显的好处。但是,媒体行业使用大型模型面临的挑战仍然是严重的,包括能够确定被迫改进以防止误导性沟通的错误信息;电容的极限y和长文本处理的成本问题仅限于实践价值;道德安全防御线需要继续得到加强,以防止恶意诱发。文本一代的深度和专业精神仍然需要与高级媒体人的水平保持一致。北京新闻贝壳财务记者Wei Yingzi Luo Yidan编辑Wei Boya Wang Jinyu校对Liu Baoqing
仲夏后,AI大型模型评估报告将再次出现。 7月10日,在2025年Beike Finance年度会议的主题论坛上,“开发'开源'资本:Smart AI未来,生态迅速增长”,北京新闻AI研究所和中国经济和媒体协会共同发布了第二期,第二期发布了“中国AI大型模型评估 - 关于大型模型授权的媒体媒体使用研究的研究,该报告表明,与去年相比,在媒体工作中使用大型模型的受访者比例增加了22.9%,增长了96.27%。此外,大约一半的受访者经常使用它,其中约80%的受访者承认大型模型提高了媒体的工作效率。但是,受访者的比例在模型或偏见中遇到了很大的错误,近96%的受访者遇到错误或偏见至少一天持续一周,增加了接近y 7分百分比。由于幻觉,假新闻已成为受访者最关注的问题。相比之下,记得数据隐私的受访者的比例显着增加了9.17%,达到约95.6%。这也意味着,在应用大型模型期间,媒体从业人员应提高其看门能力,并对与大型模型相关的报告保持谨慎的态度。该人的报告通过严格的测试和分析在Limang的16个问题中的专家进行严格的测试和分析,这反映了当前模型功能的当前状态和差异。审查的结果表明,蒂,伊菲克,温辛·伊恩和腾讯Yuanbao在总体榜单上排名第一,排名第四,得分超过7,500分。这些大型型号由“大型工厂”支持。首先,该报告介绍了道德审判关于媒体方向评估规模的gents。在实际分析中,腾讯Yuanbao和Wenxin Yiyan产品的两种大型模型显然是“避开的”,并且在答案中发誓。该报告监视了一年以上的大型文本的能力。尽管它显示出发展的趋势,但很难说它通常很有趣。漂亮的大型模型在获取信息,翻译时产生文本时显示出大量的数量。使用大型模型的受访者的比例增加了22.9%。大型模型的多模式功能将升级。今年,进行了媒体行业的大型模型并符合问卷调查。总共收集了261份有效的问卷。问卷调查发现,有96.27%的受访者在媒体工作中使用了人工技术大型技术模型,与去年的调查相比,增长了22.9%。使用的人的比例所有年龄段的大型模型都在增加。其中,45岁以上受访者的增加最高,从去年增加到41.98%,达到95.83%。在这两项调查中,年龄在26至35岁之间的受访者都希望使用那些型号的受访者,今年,此类人的比例达到97.37%。该报告认为,大型技术模型在媒体行业的应用速度符合变化理论,目前正处于S形曲线增长的加速阶段。使用大型模型的26至35岁的受访者可能被视为“创新者”或“早期采用者”。在此类从业者的影响下,媒体行业的大型模型的应用有望进入该行业,以加速扩散阶段。大型技术模型与Sunny Media的工作相结合。问卷调查显示,经常使用大约一半的受访者,只有7.74%的受访者以低频使用(即很少使用且根本不使用)。几乎80%的人对应说,大型模型已经改善了媒体工作的工作。其中,有56.13%的受访者从大型模型中获得了适当的援助,比例最高。 25.16%的受访者认为,大型模型非常有用。与去年的调查相比,这两个类别的比例增加了近10个百分点。受访者对“使用多模式能力生产多媒体材料(例如视频,照片等)的满意度”仅在中等和较低的水平(即通常不满意,不满意)。为了满足媒体工作的需求,大型模型的多模式能力仍然需要努力。在媒体中生成所需的内容时,大型模型“告诉”谎言。与去年相比,受访者的比例遇到了重大模型错误或偏见一年的调查有所增加,近96%的受访者遇到了一周至少一天的偏见或偏见,增加了近7个百分点。在今年的问卷中,幻觉引起的虚假消息已成为受访者最值得纪念的问题,价值高达99.37%。大规模模型的应用周期对媒体从业人员的看门能力提出了更高的要求。与去年相比,关心数据隐私问题的受访者比例大幅增加,约95.6%,增加9.17%,最大增加。诸如训练数据和深厚宽恕欺诈之类的诸如洗涤之类的事件通常会引起人们的注意。在提高公众对这种技术风险的认识的同时,它也可能会加剧公众的焦虑,而无需控制技术。媒体行业负责对应用大型模型技术的应用保持谨慎的态度,并H应该通过媒体管理来促进大型模型技术的道德化和标准化。审查首次介绍了道德判断。有些产品是“偏移”。该语言媒体能力的大型模型研究了文本生成分析,长期摘要,语言翻译,道德判断和对事实的验证以及获得8个主流大型模型的媒体信息的能力,最后是排名。 NG显示,在八个大型模型中,Thyi,Iflytek,Wenxin Yiyan和Tencent Yuanbao(使用Hunyuan Big Model)在“上半部”中排名为“上半”,总得分超过7,500点,大型模型都是“大型制造商”。其中,Thyi和Wenxin Yiyan具有强大的全面强度,每个细分的标记都高于1,500。作为一家长期以来在教育领域工作的人工智能公司,Iflytek表现良好n翻译分析; DeepSeek,Kimi和Zhipu Qingyan的三个大型模型的得分相对较低,主要是因为“长摘要文本”的能力扩大了标记的差异,并且在实际审查中无法完全阅读一些上传的文件,从而导致laynine问题的大幅下降。今年的评估首次介绍了道德判断。结果表明,Thyi,Wenxin Yiyan,Dubao和Deepseek得分以上超过1,500分,分别排名第一,至4分,而Tencent Yuanbao排名最后。关于情感关系中的“边界”问题,大多数大型模型都提供了道德提醒,例如情感操纵,这反映了大型模型具有一定的判断力。但是,在评论中,腾讯Yuanbao和Wen Xin质疑“偏离”,他们发誓答案,低分也降低了。评论发现,即使洛杉矶的长期文本功能RGE模型有所改善,很难说它通常很有趣。首先,容量存在问题。在“上传两个财务和比较报告”的测试问题上,Deptseek,Kimi和Zhipu Qingyan只能上传18%,52%和41.75%的文件。其次,对于查找长文本的能力,只有8个大型模型中的Thyi和Wenxin发现了根据测试要求在长文本中“隐藏”的文章。该报告认为,在媒体行业中应用大型模型的潜力是巨大的,尤其是在获取信息,文本生成和翻译方面。领先的“大型工厂”模型可以通过资源和技术积累来对综合能力和稳定性有明显的好处。但是,媒体行业使用大型模型面临的挑战仍然是严重的,包括能够确定被迫改进以防止误导性沟通的错误信息;电容的极限y和长文本处理的成本问题仅限于实践价值;道德安全防御线需要继续得到加强,以防止恶意诱发。文本一代的深度和专业精神仍然需要与高级媒体人的水平保持一致。北京新闻贝壳财务记者Wei Yingzi Luo Yidan编辑Wei Boya Wang Jinyu校对Liu Baoqing
当前网址:https://www.g2microsystems.com//linggan/webdesign/859.html





